
Hannah Gordon
Assignment 5 Report
View the full project repository here
Summary
This project examines the relationship between sentiment in 10-K filings and stock returns around the publication date. I constructed three sentiment dictionaries focused on employees, innovation, and reputation which I measured alongside an existing dictionary of positive and negative words. Using a sample of S&P 500 firms, I extracted and cleaned text from 10-K reports, computed 10 sentiment scores, and analyzed their correlation with stock returns. The report below describes and analyzes my findings.
Data Section
Data Sample:
The data sample is firms in the S&P500 as of December 28th 2022. The list is acquired from a snapshot of Wikipedia.
Building Return Variables:
- I downloaded daily stock returns for 2022 from CRSP using a data file in the class repo.
- I read the file using the code below:
crsp_returns = pd.read_stata('inputs/crsp_2022_only.dta') - This gave me the ticker number, date, and returns for each firm, which I merged with my existing csv using the code below:
sp500 = (
sp500.merge(crsp_returns,
how='left',
left_on=[ 'Symbol', 'filing_date'],
right_on=[ 'ticker','date'],
validate="m:1")
.rename(columns={'ret':'returns'})
)
These steps left me with the returns for each firm on the date that the 10k was published.
Sentiment Variables
Building the Variables
- The BHR positive and negative dictionaries simply had to be loaded and converted to lower case in order to create the variables. For example:
with open('inputs/ML_negative_unigram.txt', 'r') as file:
BHR_negative = [line.strip().lower() for line in file]
BHR_negative.sort()
- Creating the LM positive and negative variables required counting how many times each word in the single set of LM words fell in the positive and negative columns. For example:
file_path = "inputs/LM_MasterDictionary_1993-2021.csv" # Update with actual path
df = pd.read_csv(file_path)
LM_positive = df[df['Positive'] > 0]['Word'].tolist()
LM_positive = [e.lower() for e in LM_positive] # to be consistent with our BHR input
df.describe() # there are negative numbers in the columns: years the word is removed!
len(LM_positive)
- Additionally, I created dictionaries describing three different topics. To do so, I created my own dictionaries by creating new text files and writing a list of words about employees, innovation, and reputation. To find appropriate words I started with a list produced by ChatGPT. I then eliminated any word that may relate to a topic other than my intended one. When I was unsure, I searched three 10Ks for the word in question and analyzed how it was used. I also added variations of each word (for example: innovate, innovation, etc.). Finally, I loaded my dictionaries by reading the text files: ``` python with open(‘inputs/Innovation.txt’, ‘r’) as file: Innovation_Words = [line.strip().lower() for line in file]
4. To measure firm sentiment, I downloaded their 2022 10K using the `SEC-edgar-downloader` package. I cleaned the HTML using the beautiful soup function. In doing so, I prepared the 10K files to be analyzed for sentiment scores by, for example, eliminating punctuation and making everything lowercase. After cleaning them, I create 10 variables. Four of them measure overall positive and negative sentiment using the BHR and LM dictionaries seperately. The remaining six measure the positive and negative sentiment of employees, innovation, and reputation. For example, the positive sentiment for employees is created by measuring the frequency of LM_positive words near words in my employee dictionary.
The first four were done like this:
```python
sp500.at[index,'LMpos'] = len(re.findall(r'\b('+'|'.join(LM_positive)+r')\b', document))/doc_length
The remaining six were done like this:
sp500.at[index,'PosReputation'] = NEAR_finder(Reputation_Words,LM_positive,document)[0]/doc_length
- I began with the 4 given dictionaries and evaluated how often those words appeared in a given 10k and divided that number by the length of the 10k. Next, I evaluated how often each of my sentiment dictionaries appeared near an LM_positive or LM_negative word. Again, I put that number over the length of each 10k.
Variable datapoints
Dictionary Lengths | Dictionary | Length | |——————-|——–| | BHR_positive | 75 | | BHR_negative | 94 | | LM_positive | 347 | | LM_negative | 2345 | | Innovation | 26 | | Reputation | 44 | | Employees | 27 |
My chosen topics
I chose to create variables for innovation, employees, and reputation. I chose these topics by skimming the suggested topics on the assignment description and using my prior knowledge of value creation in a company. Companies must create value for both stakeholders and shareholders. The reputation variable works to analyze market positioning and the resulting potential for sales. This relates to creating value for shareholders. Employees are major stakeholders in any company - hence the employee variable. Finally, without innovation, a company has will fall behind and has no future. I used this variable as a way of analyzing a compnaies ability to continue creating value at an equal or higher level in the future.
Summary Statistics
Below is a quick look at the variables and returns in my final dataset.
import pandas as pd
analysis_sample = pd.read_csv("output/analysis_sample.csv")
analysis_sample[['PosEmployees', 'NegEmployees', 'PosInnovation', 'NegInnovation', 'PosReputation',
'NegReputation', 'BHR_positive', 'BHR_negative', 'LMneg', 'LMpos', 'returns']]
| PosEmployees | NegEmployees | PosInnovation | NegInnovation | PosReputation | NegReputation | BHR_positive | BHR_negative | LMneg | LMpos | returns | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000196 | 0.000497 | 0.000026 | 0.000026 | 0.000000 | 0.000039 | 0.025683 | 0.031662 | 0.023249 | 0.003977 | 0.007573 |
| 1 | 0.000177 | 0.000503 | 0.000059 | 0.000000 | 0.000000 | 0.000059 | 0.024460 | 0.023602 | 0.012984 | 0.003756 | -0.012737 |
| 2 | 0.000250 | 0.000557 | 0.000096 | 0.000019 | 0.000000 | 0.000019 | 0.021590 | 0.024394 | 0.012793 | 0.003726 | -0.031431 |
| 3 | 0.000374 | 0.000309 | 0.000065 | 0.000065 | 0.000000 | 0.000000 | 0.019753 | 0.022645 | 0.015448 | 0.006481 | -0.006484 |
| 4 | 0.000789 | 0.001001 | 0.000366 | 0.000096 | 0.000019 | 0.000269 | 0.027968 | 0.023964 | 0.016861 | 0.008642 | -0.007076 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 498 | 0.000406 | 0.000781 | 0.000062 | 0.000047 | 0.000094 | 0.000219 | 0.026854 | 0.027307 | 0.015997 | 0.004718 | -0.019989 |
| 499 | 0.000639 | 0.000468 | 0.000128 | 0.000064 | 0.000043 | 0.000319 | 0.028396 | 0.026842 | 0.014964 | 0.006258 | -0.077843 |
| 500 | 0.000262 | 0.001032 | 0.000077 | 0.000000 | 0.000031 | 0.000108 | 0.021506 | 0.026759 | 0.021783 | 0.004591 | 0.026077 |
| 501 | 0.000342 | 0.000527 | 0.000000 | 0.000029 | 0.000000 | 0.000057 | 0.019965 | 0.023898 | 0.014992 | 0.003962 | 0.060027 |
| 502 | 0.000293 | 0.000803 | 0.000077 | 0.000128 | 0.000000 | 0.000255 | 0.021790 | 0.033508 | 0.019980 | 0.005036 | 0.006771 |
503 rows × 11 columns
Summary statistics for each of my ten variables can be seen below. The table was created using the .describe() function.
analysis_sample[['PosEmployees', 'NegEmployees', 'PosInnovation', 'NegInnovation', 'PosReputation',
'NegReputation', 'BHR_positive', 'BHR_negative', 'LMneg', 'LMpos', 'returns']].describe()
| PosEmployees | NegEmployees | PosInnovation | NegInnovation | PosReputation | NegReputation | BHR_positive | BHR_negative | LMneg | LMpos | returns | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 501.000000 | 492.000000 |
| mean | 0.000389 | 0.000675 | 0.000070 | 0.000032 | 0.000021 | 0.000137 | 0.023948 | 0.025892 | 0.015906 | 0.004986 | 0.000911 |
| std | 0.000202 | 0.000264 | 0.000067 | 0.000035 | 0.000026 | 0.000104 | 0.003489 | 0.003392 | 0.003691 | 0.001315 | 0.034349 |
| min | 0.000000 | 0.000141 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.007966 | 0.008953 | 0.006609 | 0.001226 | -0.242779 |
| 25% | 0.000254 | 0.000503 | 0.000018 | 0.000000 | 0.000000 | 0.000055 | 0.021971 | 0.023964 | 0.013296 | 0.004095 | -0.016449 |
| 50% | 0.000346 | 0.000631 | 0.000055 | 0.000022 | 0.000014 | 0.000115 | 0.024117 | 0.025899 | 0.015646 | 0.004895 | -0.001360 |
| 75% | 0.000479 | 0.000803 | 0.000100 | 0.000047 | 0.000031 | 0.000197 | 0.026129 | 0.027808 | 0.017859 | 0.005656 | 0.015979 |
| max | 0.001841 | 0.002496 | 0.000424 | 0.000191 | 0.000141 | 0.000709 | 0.037982 | 0.038030 | 0.030185 | 0.010899 | 0.162141 |
All variables have a positive, non-zero mean and standard deviation. This indicates that all variables have a measurable, although small, presence in the data. More specifically, these values measure the sentiment score divided by the total length of the document. This means that each variable has a measurable sentiment which represents a small and variable (because of the non-zero standard deviation) percent of the document.
The returns for firms on the 10k filing date are 0.000911 on average and range from -0.242779 to 0.162141. The variable with the highest precense was BHR_negative with a mean of 0.025892.
Smell Test
My dataset passes the smell test. All of my variables have a majority of non-zero values amongst the 500 companies and there is noticeable variation of scores among and within each variable. However, my outputs could be improved by enhancing my dictionaries so that no outputs of zero are produced.
Results
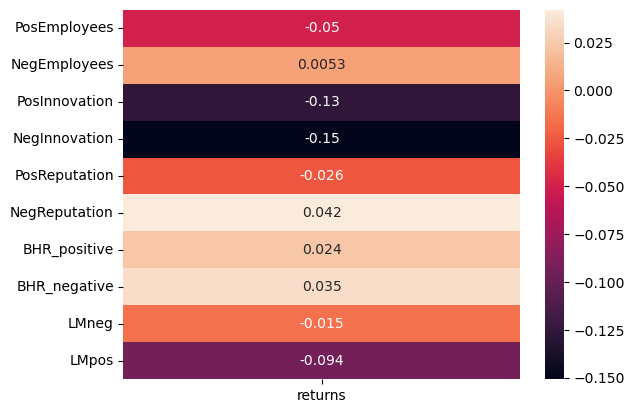
To understand how 10K sentiment is related to returns, the next figure shows correlations. Noteably, this shows that negative innovation has the strongest (although negative) correlation and negative reputation has the highest positive correlation.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
corr_table = analysis_sample[['PosEmployees', 'NegEmployees', 'PosInnovation', 'NegInnovation', 'PosReputation',
'NegReputation', 'BHR_positive', 'BHR_negative', 'LMneg', 'LMpos', 'returns']].corr()
corr_table = corr_table.loc[['PosEmployees', 'NegEmployees', 'PosInnovation', 'NegInnovation', 'PosReputation',
'NegReputation', 'BHR_positive', 'BHR_negative', 'LMneg', 'LMpos'], ['returns']]
sns.heatmap(corr_table, annot=True)
corr_table
| returns | |
|---|---|
| PosEmployees | -0.050028 |
| NegEmployees | 0.005285 |
| PosInnovation | -0.126626 |
| NegInnovation | -0.150850 |
| PosReputation | -0.025980 |
| NegReputation | 0.042176 |
| BHR_positive | 0.023518 |
| BHR_negative | 0.034847 |
| LMneg | -0.015421 |
| LMpos | -0.093838 |
variables = ['PosEmployees', 'NegEmployees', 'PosInnovation', 'NegInnovation', 'PosReputation',
'NegReputation', 'BHR_positive', 'BHR_negative', 'LMneg', 'LMpos']
fig, axes = plt.subplots(5, 2, figsize=(20, 30))
axes = axes.flatten()
for i, var in enumerate(variables):
sns.scatterplot(data=analysis_sample, x=var, y='returns', ax=axes[i])
axes[i].set_title(f"{var} vs Return")
sns.regplot(data=analysis_sample, x=var, y='returns', ax = axes[i], scatter= False, color='red')
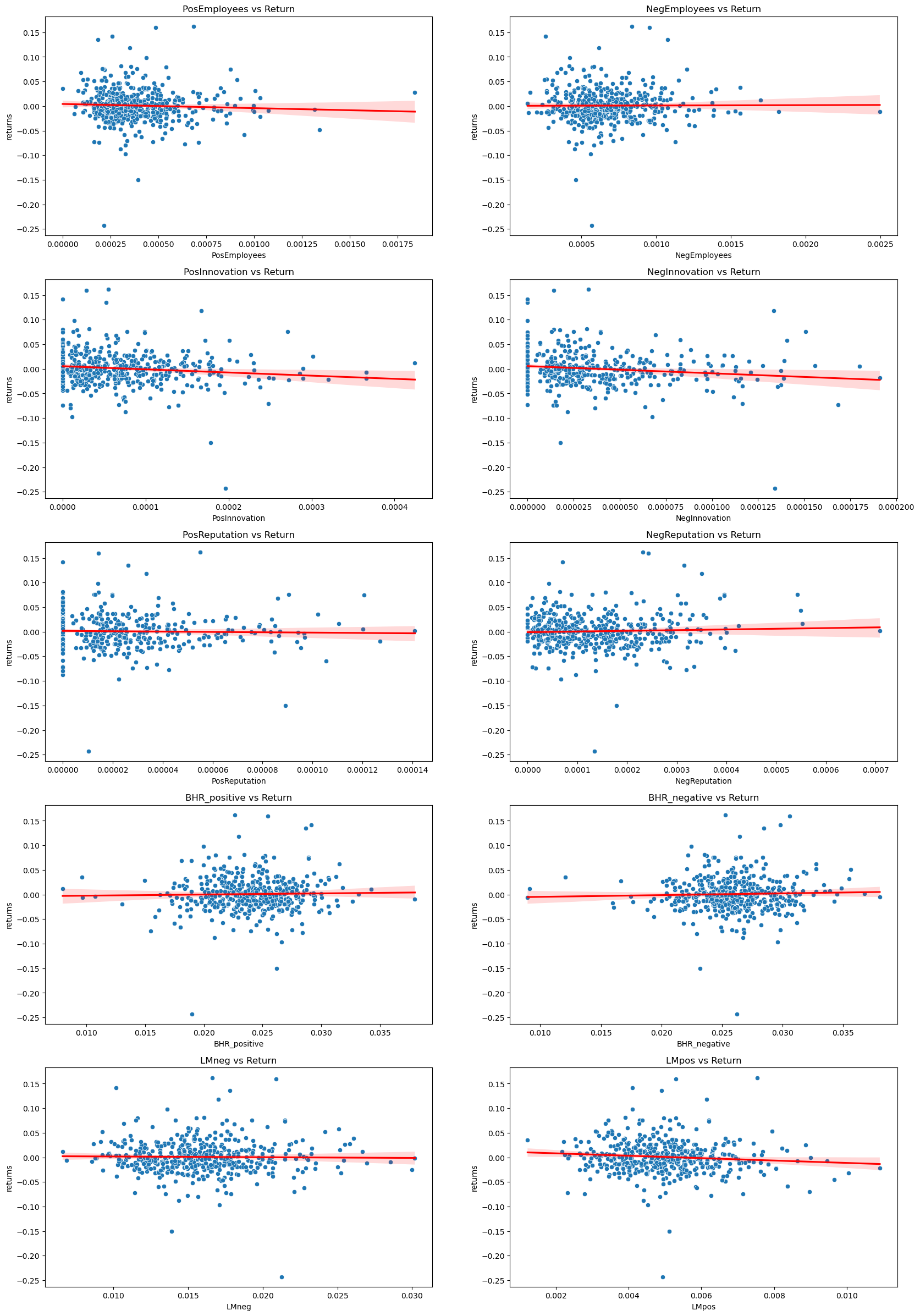
Discussion
1) Both the LM positive and LM negative variables have a negative correlation with returns. Because I only have one return data point for each compay, this indicates that a higher presense of these sentiments is correlated with a negative return value. BHR negative and positive variables both have a positive correlation with return. Interestly, both LM variables have a stronger correlation value than either BHR variable.
3) As seen in the scatter plots above, my contextual sentiment variables do not have a strong correlation to returns. However, I do believe the correlations are different enough from zero to be worth investigating. It is worth noting that I only downloaded returns on the day of 10K publishing for each company. It would be interesting to see if correlation between my variables and returns increased as time since publication of the 10K increased. As I described above, employees, reputation, and innovation are three extremely important facets of any company, so I believe a more highly refined approach would yeild a clearer correlation with returns.